Radar Inżynierii Agentowej — raport (wydanie Q2 2026)
Towarzysz Radaru Inżynierii Agentowej — 28 praktyk budowania systemów z LLM na 4 sektorach × 4 pierścieniach dojrzałości. Autor: Szymon Paluch. „Deterministyczna kontrola nad niedeterministycznym AI — z okopów, nie ze slajdów."
Sekcje 1–3 są otwarte; deep-dive (4–8) za bramką e-mail. Wypełnij assessment „AI-Loops Readiness", by poznać swoją pozycję na radarze.
Streszczenie wykonawcze + 5 odczytów
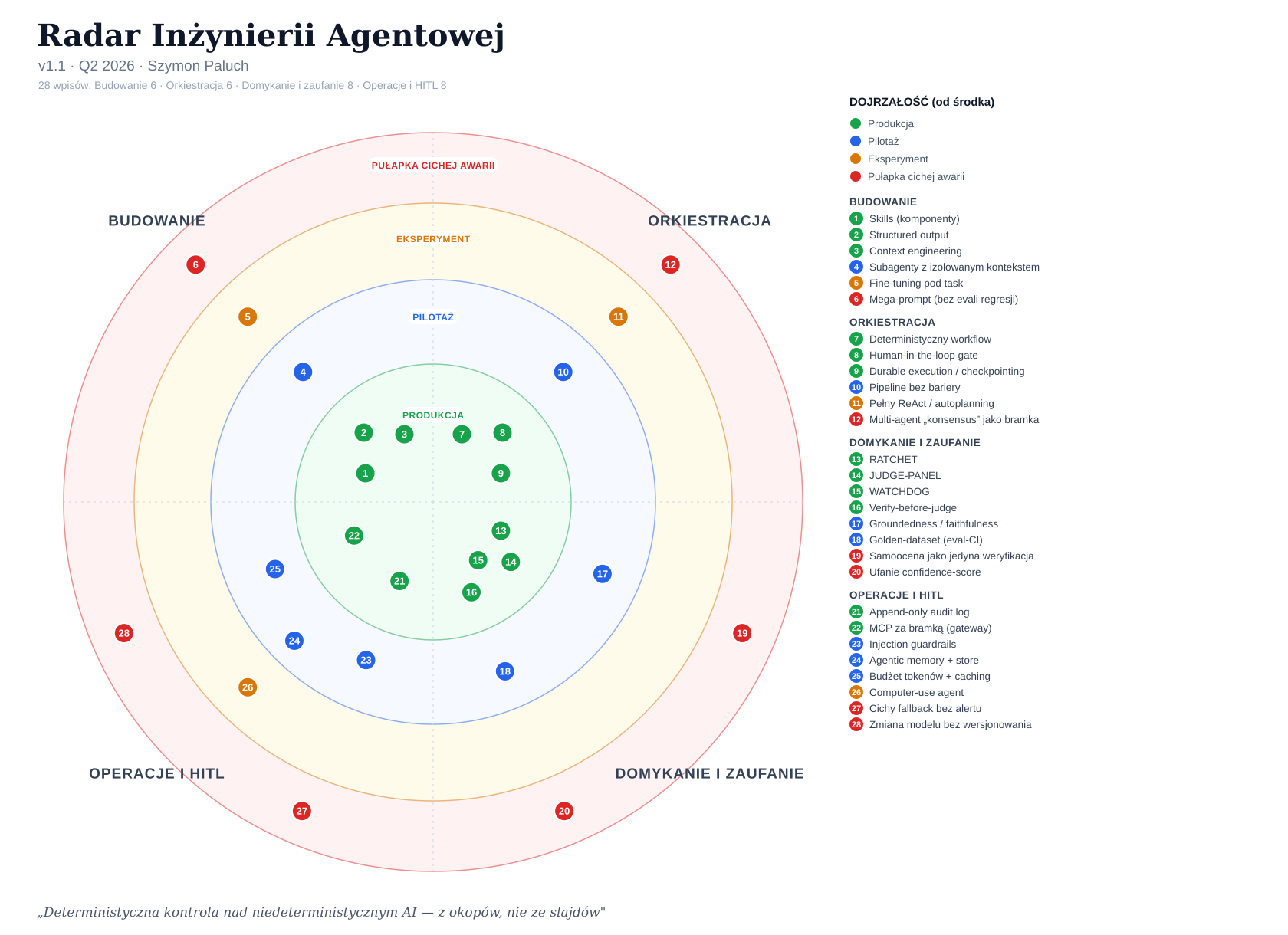
Ten dokument tłumaczy Radar Inżynierii Agentowej — mapę 28 praktyk budowania systemów z LLM, posortowanych nie wedle tego, co dobrze brzmi na konferencji, ale wedle tego, co faktycznie dowozi w produkcji. Każdy z 28 wpisów leży w jednym z czterech pierścieni dojrzałości (Produkcja / Pilotaż / Eksperyment / Pułapka cichej awarii) i w jednym z czterech sektorów (Budowanie 6, Orkiestracja 6, Domykanie i zaufanie 8, Operacje i HITL 8). Radar powstał z okopów, nie ze slajdów: porządkuje techniki według dwóch osi, które naprawdę decydują o losie wdrożenia — kto trzyma control flow (model czy Ty) i czy istnieje pętla, która weryfikuje output, zamiast brać go na słowo. Czerwona nić jest jedna: AI skaluje bałagan, inżynieria skaluje jakość. Przestań promptować — buduj pętle. Wtedy jedna osoba dowozi jak zespół, bo output to produkcja, a nie slop.
Uwaga na dwa różne wymiary, których nie wolno mylić: pierścień dojrzałości ≠ ćwiartka mapy X/Y. Pierścień mówi, jak sprawdzona jest dana mechanika w boju. Ćwiartka mówi, kto trzyma kontrolę i czy istnieje pętla domykająca. Wpis może być w pierścieniu Produkcja jako dojrzała mechanika, a mimo to nie domykać jakości — i wtedy ląduje w Kruchej kontroli (Y<50), nie w Operatorze produkcyjnym. Tak jest ze Structured output („Produkcja z gwiazdką" — schema waliduje kształt, nie jakość), Context engineering, Skills i MCP za bramką: to solidne klocki, ale same z siebie nie weryfikują outputu.
Pięć odczytów, które edycja uznała za najważniejsze:
- Wszystko, co robi „wow" na scenie, siedzi w pierścieniu pułapek lub eksperymentu. Mega-prompt, multi-agentowy „konsensus", pełny ReAct/autoplanning, computer-use, samoocena modelu — to demówki, które świetnie wyglądają na żywo i cicho się wykrzaczają w czwartek o 2:00. Atrakcyjność sceniczna jest odwrotnie skorelowana z gotowością produkcyjną. Im bardziej coś robi efekt na widowni, tym ostrożniej traktuj to w realnym systemie.
- Osiem produkcyjnych wpisów z sektorów Orkiestracja, Domykanie i Operacje opisuje jeden i ten sam wzorzec: człowiek trzyma control flow + pętla domyka jakość. Deterministyczny workflow, HITL-gate, durable execution, RATCHET, JUDGE-PANEL, WATCHDOG, verify-before-judge i append-only audit log — żaden z tych wpisów nie oddaje control flow modelowi i żaden nie ufa outputowi bez zewnętrznego domknięcia. To nie przypadek: dokładnie te osiem leży w ćwiartce Operator produkcyjny (X≥50, Y≥50) — jedynej, w której da się spać spokojnie. To NIE to samo co cały pierścień Produkcja: pozostałe wpisy produkcyjne (Skills, Structured output, Context engineering, MCP za bramką) to dojrzała mechanika, która waliduje kształt albo dostarcza klocki, ale sama jakości nie domyka — i część z nich siedzi w Kruchej kontroli (Y<50). Produkcyjna dojrzałość to za mało; o ćwiartce decyduje pętla.
- Najgroźniejsze pułapki udają sukces — status=ok, output=śmieci. Cichy fallback bez alertu (wg Datadoga ~1/3 błędów agentowych to zwykłe rate-limity, których nikt nie zobaczył), zmiana modelu/promptu bez wersjonowania, regresja mega-promptu po edycji fragmentu. System nie krzyczy, dashboard świeci na zielono, a jakość już dawno spadła. Dlatego osobny pierścień „Pułapka cichej awarii" istnieje na radarze — bo brak czerwonej lampki to nie to samo co poprawność.
- Weryfikacja bez zewnętrznego yardsticka to teatr. Samoocena modelu (self-preference bias — sędzia lubi własne odpowiedzi), ufanie confidence-score (pewność ≠ poprawność), multi-agentowy „konsensus" (zgoda agentów czyta się jak weryfikacja, a to echo tej samej halucynacji) — wszystkie trzy symulują kontrolę, nie dając jej. Prawdziwe domknięcie wymaga niezmiennego punktu odniesienia z zewnątrz: RATCHET (immutable yardstick, keep-if-better/revert — dowód: 0,83 Spearmana na OffBall), golden-dataset jako bramka regresji, sędzia adwersaryjny z zamianą pozycji. Jeśli system ocenia sam siebie, nie ma weryfikacji — ma lustro.
- Zmiana modelu pod spodem to ukryta bomba. Dostawca po cichu podbija wersję, Ty zamieniasz „szybszy" model dla oszczędności, ktoś tweakuje prompt „tylko trochę" — i bez wersjonowania + golden-dataset w CI cicha regresja wchodzi na produkcję bez jednego logu. To najtańsza katastrofa do uniknięcia (wystarczy eval-bramka) i najczęstsza do przeoczenia.
Mapa do czterech ćwiartek metodologicznych:
| Ćwiartka | Kontrola wykonania (X) | Domknięcie (Y) | Czytaj jako |
|---|---|---|---|
| Ruletka | model decyduje (<50) | ufasz na słowo (<50) | demo, nie system |
| Krucha kontrola | Ty trzymasz (≥50) | brak weryfikacji (<50) | działa, aż przestanie — po cichu |
| Nadgorliwa weryfikacja | model decyduje (<50) | pętla weryfikuje (≥50) | drogie, niestabilne, ale uczciwe |
| Operator produkcyjny | Ty trzymasz (≥50) | pętla weryfikuje (≥50) | tu mieszka osiem domykających wpisów produkcyjnych |
Reszta dokumentu rozkłada każdy z 28 wpisów na czynniki pierwsze i pokazuje, jak trzy wzorce domykające — RATCHET, JUDGE-PANEL, WATCHDOG — przenoszą system z lewej połowy mapy do ćwiartki, w której jedna osoba dowozi jakość zespołu.
Metodologia: dwie osie (jak czytam radar)
Radar Inżynierii Agentowej to 28 wpisów rozłożonych na mapie o dwóch osiach. Mapa nie mówi „to jest dobre, a to złe". Mówi coś trudniejszego: gdzie dana technika leży, jeśli traktujesz AI jak produkcję, a nie jak demo na konferencji. Placement bierze się z doświadczenia z okopów — z systemów, które chodzą u klienta i które ktoś musi naprawić, kiedy o 3 w nocy zwrócą śmieci ze statusem ok. Nie z ankiety analityka, który nigdy nie deployował.
Oś X — Kontrola wykonania (kto trzyma control flow)
Pozioma oś odpowiada na jedno pytanie: kto decyduje, co dzieje się dalej — model czy Ty?
- Lewo (X < 50): model decyduje. Oddajesz sterowanie LLM-owi. To on wybiera kolejny krok, kolejne narzędzie, kolejną gałąź. Pełny ReAct, autoplanning, „daj agentowi cel i patrz". Elastyczne, demonstracyjne, świetne na scenie. W produkcji — niedeterministyczne i trudne do odtworzenia, gdy coś pójdzie nie tak.
- Prawo (X ≥ 50): Ty trzymasz control flow. Przepływ jest Twój — kod, graf, workflow. Model jest wezwany do konkretnego kroku, dostaje wąsko zdefiniowane zadanie, oddaje wynik, a logika sterująca zostaje po Twojej stronie. To jest dokładnie „przestań promptować, buduj pętle": jedna osoba dowozi jak zespół, bo output jest powtarzalny.
Oś X nie mierzy inteligencji. Mierzy, gdzie siedzi niedeterminizm. Im bardziej w prawo, tym mniej miejsc, w których model może po cichu zboczyć z trasy.
Oś Y — Domknięcie / weryfikacja (czy ufasz na słowo, czy sprawdzasz)
Pionowa oś odpowiada na drugie pytanie: co się dzieje z outputem, zanim uznasz go za gotowy?
- Dół (Y < 50): ufasz na słowo. Model coś zwrócił, status
ok, idziemy dalej. Brak pętli weryfikującej. Zakładasz, że skoro nie poleciał wyjątek, to wynik jest dobry. Tu mieszka cicha awaria. - Góra (Y ≥ 50): pętla weryfikuje. Output przechodzi przez domknięcie — deterministyczny check, panel sędziów, ratchet, watchdog, golden-dataset w CI. Zanim coś trafi dalej, coś to sprawdziło wedle reguły, której model nie może sobie nagiąć.
Oś Y to serce tezy „AI skaluje bałagan; ja skaluję jakość". Bez domknięcia skalujesz tylko prędkość generowania slopu.
Kolor — ryzyko cichej awarii (100 − Y)
Każdy wpis ma kolor liczony wprost z osi Y: ryzyko cichej awarii = 100 − Y. Im niżej leży technika (mniej weryfikacji), tym goręcej świeci. To nie ozdoba — to przypomnienie, że najgroźniejsze nie jest to, co głośno pada z wyjątkiem, tylko to, co zwraca status=ok przy output=śmieci. Czerwień na mapie = „tu nikt nie patrzy na ręce modelowi".
Cztery ćwiartki
Przecięcie obu osi w punkcie 50/50 daje cztery ćwiartki. Tak czytam każdy z 28 wpisów.
| Ćwiartka | Warunek | Co to znaczy w praktyce |
|---|---|---|
| Ruletka | X < 50, Y < 50 | Model decyduje i nikt nie sprawdza. Najwyższe ryzyko cichej awarii. Demo wygląda magicznie, produkcja krwawi po cichu. |
| Krucha kontrola | X ≥ 50, Y < 50 | Trzymasz przepływ, ale nie domykasz. Powtarzalne wykonanie, zerowa pewność jakości — regresja po edycie fragmentu przejdzie niezauważona. |
| Nadgorliwa weryfikacja | X < 50, Y ≥ 50 | Weryfikujesz solidnie, ale oddałeś sterowanie modelowi. Płacisz za check tam, gdzie wystarczyłby deterministyczny krok — drogo i wolno. |
| Operator produkcyjny | X ≥ 50, Y ≥ 50 | Ty trzymasz control flow i pętla weryfikuje. Cel docelowy. Tu mieszka „jedna osoba dowozi jak zespół". |
Strzałka, którą wyznacza cały radar, biegnie z lewego-dolnego rogu (Ruletka) do prawego-górnego (Operator produkcyjny). Nie chodzi o to, żeby każdy wpis był w prawym górnym rogu — chodzi o świadomość, gdzie stoisz i co dokładnie Cię tam trzyma.
„Z okopów, nie z ankiet" — czym to się różni od Gartnera
Klasyczny radar/Magic Quadrant powstaje z ankiet, wywiadów z vendorami i agregacji opinii rynku. Świetne do slajdu zarządczego, bezużyteczne, gdy masz zdeployować pętlę agentową, która nie wybuchnie. Tu placement bierze się z doświadczenia produkcyjnego — z tego, co naprawdę przeżyło kontakt z klientem, a nie z tego, co najczęściej zaznaczają respondenci. To jest świadomie anty-Gartner: nie pytam rynku, co jest modne; mówię, gdzie technika ląduje, kiedy odpowiadasz za jej output. Dlatego np. „multi-agent konsensus jako bramka" nie awansuje za hype — zgoda agentów czyta się jak weryfikacja, a bywa echem tej samej halucynacji, więc ląduje w Pułapce, nie w Produkcji.
Cztery pierścienie dojrzałości
Niezależnie od pozycji X/Y, każdy z 28 wpisów dostaje pierścień — odpowiedź na pytanie „na ile możesz na tym polegać dziś, w czerwcu 2026":
| Pierścień | Znaczenie | Decyzja operacyjna |
|---|---|---|
| Produkcja | Sprawdzone w boju, przewidywalne, warte zaufania pod obciążeniem. | Wdrażaj. To fundament. |
| Pilotaż | Działa, ale wymaga nadzoru, tuningu i świadomości granic. | Wdrażaj ostrożnie, z monitoringiem i bramką. |
| Eksperyment | Obiecujące, niedojrzałe, kosztowne lub zawodne na pierwszej próbie. | Testuj na boku, nie stawiaj na tym produkcji. |
| Pułapka cichej awarii | Wygląda jak rozwiązanie, w praktyce produkuje status=ok / output=śmieci. | Unikaj jako bezpiecznika. Rozpoznawaj, żeby nie wpaść. |
Najważniejszy z nich jest ostatni. Pierścień Pułapki cichej awarii to jedyny, którego nie znajdziesz na radarze sklejonym z ankiet — bo nikt w ankiecie nie przyzna, że jego „bramka weryfikacyjna" to halucynacja sprawdzana inną halucynacją. To miejsce dla technik, które brzmią dojrzale, a w produkcji są pułapką: samoocena jako jedyna weryfikacja, ufanie confidence-score, mega-prompt bez evali, cichy fallback bez alertu. Rozpoznanie ich to połowa inżynierii pętli agentowych — bo cicha awaria nie krzyczy. Trzeba ją złapać, zanim sama się ujawni na fakturze klienta.
Cicha awaria — czemu istnieje zewnętrzny pierścień
Najgorszy błąd AI to nie ten, który wywala stack trace. To ten, który wraca z status: ok i wygląda na zrobiony — a w środku jest śmieć. Nazywam to cichą awarią: system raportuje sukces, output jest fałszywy, i nikt się nie dowiaduje, dopóki ktoś nie podejmie decyzji na podstawie tego śmiecia. Dlatego na całym radarze cicha awaria nie jest jednym z pierścieni dojrzałości — jest osobnym, sygnaturowym pierścieniem zewnętrznym. To nie „mniej dojrzała wersja produkcji". To inna kategoria ryzyka, która potrafi dotknąć dowolny z 28 wpisów — łącznie z tymi, które poza tym wyglądają dojrzale.
Definicja: dwa stany, które muszą się zgadzać
Klasyczny błąd softwarowy łamie jedną rzecz: program się wywala albo zwraca błąd. Łatwo to złapać — jest wyjątek, jest alert, jest czerwony log. Awaria AI łamie rozjazd między dwoma osiami naraz:
| Wymiar | Klasyczny błąd | Cicha awaria AI |
|---|---|---|
| Status techniczny | error / exception | ok / 200 / „done" |
| Treść outputu | brak / oczywiście pusta | wygląda kompletnie i sensownie |
| Wykrywalność | natychmiastowa (alert, crash) | dopiero przy ręcznej weryfikacji albo skutkach |
| Koszt | ograniczony, lokalny | rośnie z czasem — decyzja zapadła na śmieciu |
| Kto wykrywa | monitoring | człowiek, zwykle za późno |
Sedno: status mierzy, czy pipeline się wykonał. Nie mierzy, czy output jest prawdziwy. Te dwie rzeczy mylą się tylko w świecie deterministycznym, gdzie „wykonało się" implikuje „zrobiło to, co miało". W świecie niedeterministycznego AI to dwie zupełnie różne gwarancje — a większość zespołów monitoruje tylko pierwszą.
Czemu pilotaże umierają właśnie tutaj
Każda firma, do której przychodzę, już próbowała AI. Prawie żadna nie powie „nie działało". Powiedzą coś gorszego: „działało, ale nie możemy na tym polegać". To jest dokładnie sygnatura cichej awarii i to jest moment, w którym umiera większość pilotaży.
Mechanizm jest zawsze ten sam. Demo robi się na trzech ładnych przykładach — i działa. Wchodzi na produkcję, gdzie dane są brzydkie, brzegowe i złośliwe. System dalej zwraca ok na wszystkim, więc nikt nie zauważa, że jakość spadła. Po kilku tygodniach ktoś z biznesu łapie wynik, który jest oczywistym nonsensem — i to wystarczy. Zaufanie pęka nie dlatego, że AI się myli (ludzie też się mylą), tylko dlatego, że myli się z pełną pewnością i bez ostrzeżenia. Po jednym takim incydencie projekt dostaje etykietę „slop generator" i ląduje w zamrażarce. Nie z powodu błędu, który ktoś naprawił, tylko z powodu klasy błędu, której nikt nie widział.
To dlatego sprzedaję domykanie pętli, a nie kolejny model. Firma, która już oberwała slopem, nie kupi „lepszego promptu". Kupi dowód, że tym razem śmieć zostanie złapany, zanim trafi do decyzji.
Trzy mechanizmy (anonimizowane)
Pokażę trzy realne wzorce, na które się natknąłem. Różne domeny, ten sam podpis: zielony status, fałszywa treść.
1. Halucynowany argument narzędzia. Agent z dostępem do API woła funkcję z poprawnym schematem, ale zmyślonym parametrem — np. ID rekordu, który nie istnieje, albo zakres dat złożony z prawdopodobnie wyglądających liczb. structured output przepuszcza to bez mrugnięcia, bo schema waliduje kształt, nie prawdę — pole jest stringiem, więc jest „valid". Narzędzie zwraca pusty albo przypadkowy wynik, agent owija go w pewną siebie odpowiedź, pipeline kończy się ok. Nigdzie nie ma błędu. Jest tylko zła odpowiedź podana jak fakt.
2. Cichy fallback po rate-limicie. Pod obciążeniem dostawca odbija część wywołań (429). Kod ma „defensywny" fallback: gdy model nie odpowie, podstaw wartość domyślną / ostatni dobry wynik / pusty obiekt i jedź dalej. Bez alertu. System raportuje 100% sukcesu, podczas gdy w rzeczywistości jedna trzecia outputów to zaślepki. (W danych Datadoga z produkcji — marzec 2026 — rate-limity to blisko ⅓ wszystkich błędów wywołań LLM, a fallback je z definicji ukrywa.) Wygląda stabilnie. Jest fikcją.
3. Zmiana modelu/promptu bez wersjonowania. Ktoś podbija wersję modelu albo „poprawia" jeden akapit w mega-promptcie, żeby naprawić jeden przypadek. Naprawia ten jeden — i cicho psuje pięć innych, których nikt już nie testuje. Bez golden-datasetu i evali jako bramki regresja jest niewidoczna: output dalej wygląda dobrze, status dalej ok, a jakość osunęła się o oczko. To nie jest awaria w momencie zmiany — to mina, która wybucha tygodnie później, gdy nikt już nie kojarzy przyczyny.
Wspólny mianownik wszystkich trzech: w żadnym nie ma wyjątku do złapania. Monitoring świeci na zielono.
Czemu najgroźniejsze rzeczy udają sukces, a nie wywalają błędu
Bo niedeterministyczny model jest optymalizowany na wiarygodność, nie na prawdę. Jego zadaniem jest wyprodukować prawdopodobnie wyglądający output — i robi to równie chętnie, gdy ma rację, jak gdy zmyśla. Halucynacja nie jest stanem wyjątkowym, który da się złapać try/except. Jest normalnym, poprawnie wykonanym outputem, który akurat jest fałszywy. Z punktu widzenia maszyny stanów wszystko poszło idealnie.
I tu jest pułapka, którą najczęściej widzę: zespoły dokładają „weryfikację", która sama jest cicha. Agent ocenia własną pracę (self-preference bias — model lubi to, co sam napisał). Albo bierze się confidence score za poprawność, choć pewność to nie prawda — model bywa najpewniejszy dokładnie wtedy, gdy halucynuje. Albo stawia się trzy agenty na „konsensus", a ich zgoda czyta się jak weryfikacja, podczas gdy to echo tej samej halucynacji powielone trzy razy. Wszystkie te ruchy wyglądają jak domknięcie. Żaden nie domyka. To weryfikacja na papierze, która generuje jeszcze więcej cichej awarii — bo teraz masz fałszywy output plus fałszywy stempel „sprawdzone".
Dlatego cicha awaria to osobny pierścień
Gdyby cicha awaria była tylko „niedojrzałością", wystarczyłoby dojrzewać dalej i znika. Ale ona nie znika z dojrzałością — migruje. Dojrzały wpis z brakującą weryfikacją (np. produkcyjny pipeline bez bramki, multi-agent „konsensus" jako bramka, ufanie confidence-score) jest groźniejszy niż surowy eksperyment, bo ma więcej zaufania i więcej zasięgu. Dlatego na mapie 2-osiowej kolor = ryzyko cichej awarii liczę jako 100 − Y, gdzie Y to domknięcie/weryfikacja. Wysoka kontrola wykonania (oś X) nie ratuje — możesz mieć żelazny, deterministyczny control flow i dalej karmić nim niezweryfikowany śmieć. Jedyne, co gasi czerwień, to pętla, która sprawdza (RATCHET / JUDGE-PANEL / WATCHDOG), a nie sam porządek w orkiestracji.
Stąd cały sens radaru i jego red thread: przestań promptować, zacznij budować pętle. Zewnętrzny pierścień „Pułapka cichej awarii" istnieje po to, żeby nazwać po imieniu rzecz, której nie widać na żadnym dashboardzie — i pokazać, że to ona, a nie crash, jest powodem, dla którego AI skaluje bałagan, dopóki ktoś świadomie nie zacznie skalować jakości.